7.2 Data
There are three main types of data that we need to collect in any GNSS survey:
- Metadata – Data about our survey
- Position – GNSS Positional information about points or locations
- Attributes – location intelligence
Metadata
Our understanding where data is coming from, why it has been created, who collected it, what errors might be impacting it and how accurate it is are all critical in ensuring it is used appropriately. The creation of all this information about data is an important part of any GNSS survey. This “data about data” is referred to as metadata, and should be recorded for every GNSS survey.
Metadata allows any person to look at any dataset and understand how it was created, by whom and a whole bunch of other information. There are a number of international standards about what metadata needs to be created for spatial datasets.
In GNSS surveying, standards like SP1 and a concept called legal traceability provide a combined framework for what metadata might need to be collected for a GNSS survey. Legal traceability is the concept that there is a way to link a physical measurement to a standard.
More generally, metadata can most easily be understood as being the WHERE, WHEN, WHY, HOW, WHO and WHAT of a dataset:
- Where was the data collected?
- the physical location
- which datum or projection the data was collected in
- When was the data collected?
- Why was the data collected?
- Was it for a high accuracy survey, or just to locate the footpaths in a park?
- The WHY will give an indication of the accuracy and quality of a dataset
- How was the data collected?
- What kind of technique was used?
- What kind of equipment was used?
- What were the serial numbers, brand and model of the equipment?
- Was redundancy of measurements considered, and how was it undertaken?
- Who collected the data?
- What were the names of the people involved in the collection?
- What were their qualifications or experience in undertaking this kind of data collection?
- Who did they work for?
- Who was the client?
- Who owns the data?
- What was the data?
- What format was it collected in?
- What file types were used and what translations or transformation between file types occurred?
- Are there supporting files, like scans of field notes or photos?
- How large are the files?
- Where is the data stored?
An example of basic metadata that could be collected for a GNSS project is shown in Table 7.1(a).
Table 7.1(a): Survey metadata
| Survey site: | USQ Springfield | Name of surveyor/s: | Jane Smith |
| Date: | 01/05/2054 | Project name: | SVY1110 Tut 1 |
| GNSS antenna type: | SVMax | GNSS antenna serial number | 123456 |
| GNSS Receiver type: | SVRX | GNSS receiver serial number | 789456123 |
| Datum: | GDA2054 | Weather conditions: | Fine, 30, Slight wind |
| PM used for datum: | PM123456 | Raw data file name: | 20540501_1110.ab |
Position information
As previously discussed, the most important component of positional information is understanding the reference frame in which it is collected, and the accuracy of the data created. Both of these components are influenced by decisions made prior to any observations even being collected, and should be recorded as part of the metadata.
Showing positions to an appropriate accuracy is incredibly important, and the number of decimal places used, or the rounding used is usually the easiest way to communicate this information.
Attributes
The information we collect about what is at a position is often as important as the position itself. This location intelligence may be stored alongside the position information in a Geographic Information System or even a financial asset register – the uses for this data is incredibly varied. It can combine with other spatial datasets for the purposes of research, planning and analysis – from where schools need to go in new developments, to where the closest restaurant is to your location.
The way we describe the components that make up location intelligence is as features and attributes. In a computer science world, these could also be referred to as objects or classes, but depends on the programming language being used.
Features
A feature is an object that has both a position and a type that is either a point, a line or a polygon, and also has location intelligence. Generally, features are also used to group particular kinds of objects together, such as trees, building types or road widths.
A point feature has a single location.
A line feature is a series of point features joined together.
A polygon feature is a series of line features joined to create a closed shape or area.
The decision on which type of feature should be used to represent an object is largely reliant on how the data will be used or displayed, and to what accuracy the data needs to be collected at.
For example, if you wanted to represent all the trees in a park, you might collect them as a point if they were spread out, or if there was a dense grouping of them you might collect them as a polygon. Equally a park might be shown as a polygon if you were zoomed in closely on a map, but might be shown as a point if you were zoomed out to a city level.
Attributes and attribute values
Attributes are the information about a feature, and a feature can have multiple attributes attached to it. They are most easily considered the questions we want to ask about a feature.
For example, if we were undertaking a survey of a park, and we wanted to know whether it had a carpark, and if it does, how many carparks it had, and how many were for disabled access, the attributes could be:
- Carpark
- Number of carparks
- Number of disabled carparks
The answers to these questions are called the attribute values, the individual object’s information.
In our example of the carpark above, the attribute values could be:
- Yes or True
- 12
- 2
Attributes are sometimes referred to as aspatial data – while they don’t have a position in their own right, they are linked to a position, which is considered spatial data.
It is important to note that features might be entirely horizontal – they might not have a height attached to them.
Data formats
The way that data is collected is directly related to the way it is stored, and in most systems this is done electronically in some form of database. The allowable format of the data in a database is described by a data format.
There are any number of database systems, and each uses specific programming languages to read and write information. The language used also governs the data types used, however, some of the more common ones are covered in Table 7.1(b).
Table 7.1(b): Common data formats
| Data Type | Description | Example |
|---|---|---|
| Byte | Data | 1 |
| Short | Data | 65 |
| Int or Integer | Whole number, ranging from -2 billion to +2 billion (short scale) | 1,123,465,798 |
| Long | Whole number from -9 trillion to +9 trillion (short scale) | 1,123,456,789,123,456,789 |
| Char or Character | A single Unicode character (alphabet) | A |
| Float or Floating Point | Number with decimal places (the number of places can be specified) | 1.1234567 |
| Double | A number with up to 16 decimal places | 1.1234567891234567 |
| Boolean | True of False. Sometimes True is represented by 1 and False is represented by 0 | TRUE |
| String | Multiple characters | This is a string |
| Class | A group of objects defined by a class | Tree |
| Array | A single object that contains multiple values of the same type. Also referred to as a list. | Gum Oak |
The type of data format that we give to an attribute is called an attribute type. Attribute types allow us to generate forms that can be used to allow any user with the form to collect data in a predetermined way. This then allows us to ensure the data collected is in an appropriate format to allow for database storage and analysis.
Data priorities
While attribute types are important, deciding whether we require a particular attribute to be collected or not is also important. This decision determines whether the attribute is mandatory or optional, and is sometimes referred to as the priority of the data.
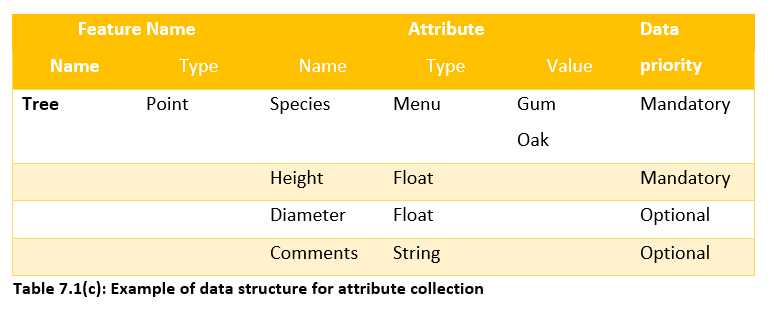
An example of all of the concepts of feature, attribute, attribute name, attribute type, attribute value and data priority are shown in Table 7.1(c).